SmartSCM Assistant: Building an AI-Powered Data Analytics Platform
How I built an intelligent multi-agent system that transforms natural language queries into automated pandas analysis.
Introduction
SmartSCM is an AI multi-agent system that turns natural language queries into pandas-based data analysis. Using LLMs and multi-agent orchestration with context-aware memory, it delivers accurate, reproducible, and scalable analytics across complex, multi-step queries. Our workflow followed these steps:
- Exploratory Data Analysis (EDA) – understanding and documenting the dataset.
- System Architecture Design – defining multi-agent structure, data pipeline, and tool integration.
- Multi-Agent Pipeline Implementation – building LLM-powered reasoning agents and tool interactions.
- Benchmarking and Evaluation – testing performance, accuracy, and robustness of the system.
Exploratory Data Analysis (EDA)
After gathering operational data from multiple sources across the organization, the data was thoroughly assessed, cleaned, explored, and merged to ensure quality and readiness for AI analysis. This phase enabled:
- Insight into data relationships and preparation for automated analysis.
- Reproducibility and reliability, with a clean, unified dataset ready for automated reporting.
- Foundation for future automation, ensuring consistent handling of new data.
- Comprehensive data documentation: Detailed metadata describing each field’s meaning, type, and purpose—critical for AI agents to reliably interpret and process the data.
 Figure 1: Dataset Documentation Structure
Figure 1: Dataset Documentation StructureSystem Architecture
Global System Architecture
The Multi-AI Agent System enables professionals to query complex datasets using natural language, eliminating the need for SQL or technical expertise.
The system integrates data sources through a data pipeline (ingestion, cleansing, transformation) into a centralized Data Lake. At the core, a multi-agent supervisor-based architecture orchestrates specialized agents that interpret queries, validate logic, execute analysis, and deliver insights—combining modularity, fault isolation, and structured control for reliable, scalable analytics.
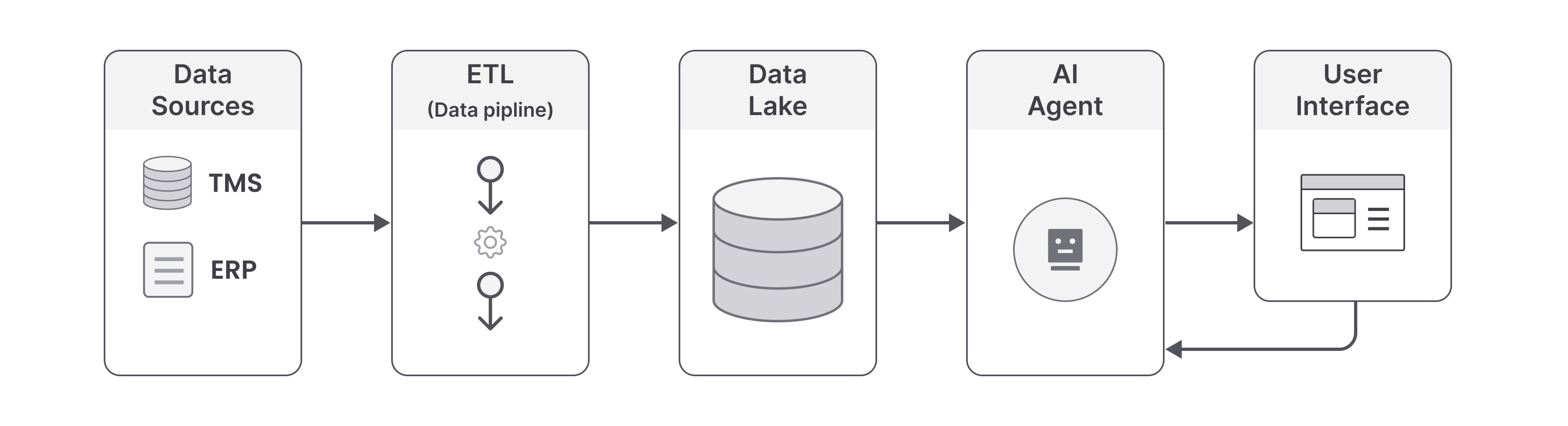 Figure 2: High-level system architecture (from data acquisition to insight delivery)
Figure 2: High-level system architecture (from data acquisition to insight delivery)Data Pipeline and Lake Architecture
The Data Lake centralizes all the data from ERP and TMS systems, separated from production databases for scalability and fault isolation. The pipeline extracts, cleans, and transforms incoming data, storing both structured tables and vectorized documents that enable intelligent context-aware searches.
This architecture supports reproducibility, monitoring, and future AI development—particularly crucial since the raw data initially lacked proper documentation.
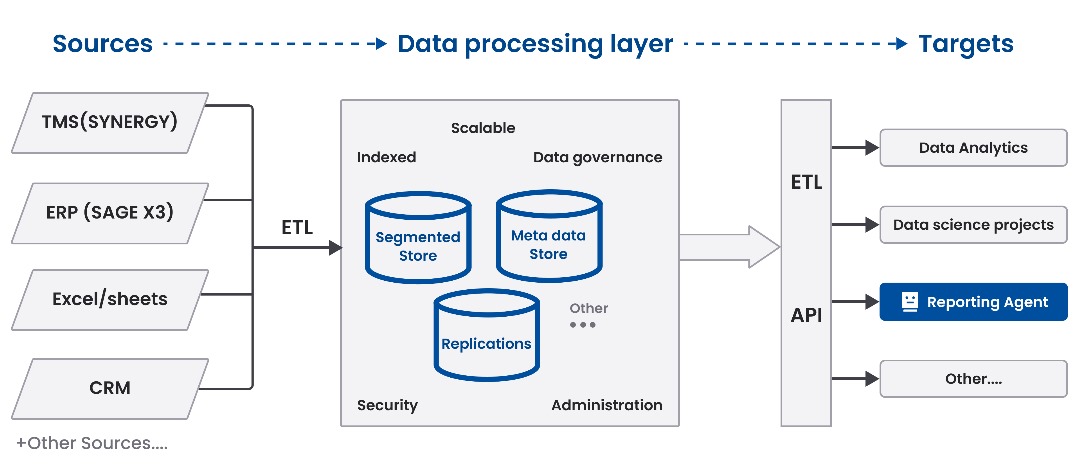 Figure 3: Overview of the Data Lake
Figure 3: Overview of the Data LakeRetrieval-Augmented Generation (RAG) Pipeline
The system uses a RAG pipeline to provide accurate, context-aware responses by retrieving only the relevant parts of the dataset documentation.
Benefits:
- Ensures the AI agents are grounded in task-specific knowledge, reducing errors.
- Minimizes token consumption, since the model only processes the documentation it needs.
- Improves response consistency and reliability, leveraging a structured, searchable knowledge base.
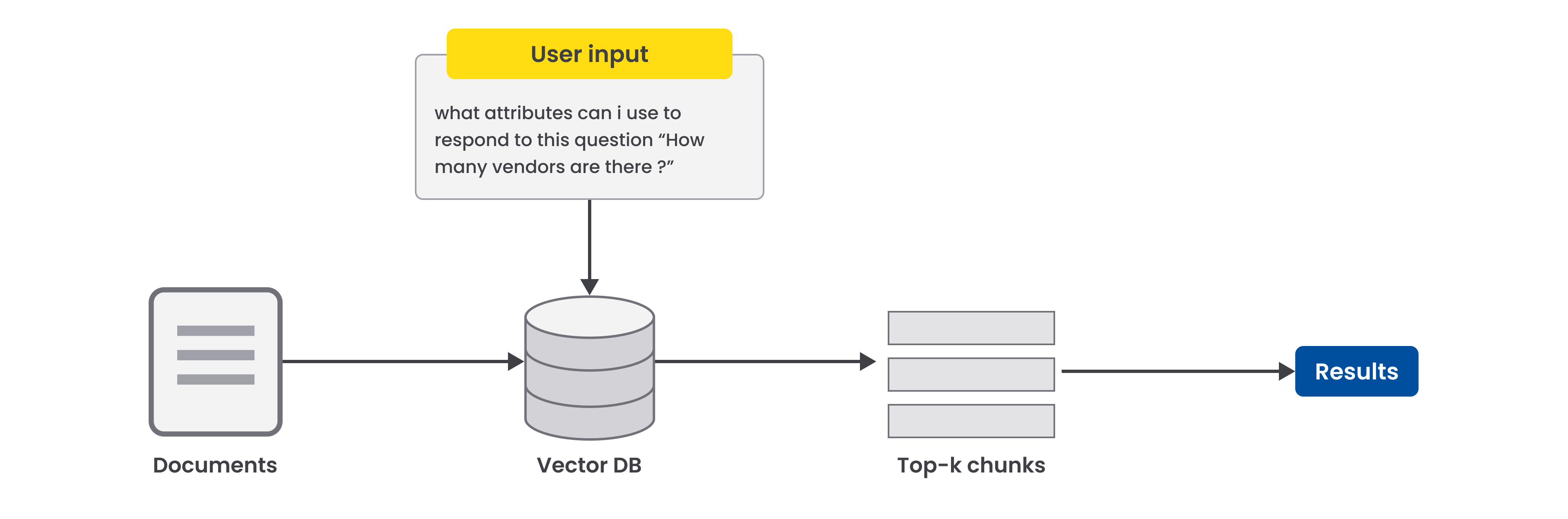 Figure 4: Overview of the RAG pipeline
Figure 4: Overview of the RAG pipelineSystem Flow and Interaction
The multi-agent system processes queries in a structured flow: the Supervisor interprets and plans the query, the Validation Agent ensures correctness, specialized agents execute tasks, and results are aggregated and presented reliably.
 Figure 5: Multi-agent system flow and interaction pattern
Figure 5: Multi-agent system flow and interaction patternExtensibility, Scalability, and Explainability
The system is modular and loosely coupled, allowing horizontal scaling by adding new agents for emerging tasks and vertical scaling with advanced AI models for predictive analytics, anomaly detection, or other workflows. Its outputs—raw, enriched, or agent-generated insights—can be integrated into dashboards, ERP modules, or decision support systems.
Transparency is central: agents’ reasoning and actions are traceable in real time, with the Validation Agent ensuring coherent plans and live step visualization making decisions auditable, understandable, and trustworthy. This combination of modularity, scalability, and explainability makes the system a reliable and flexible AI collaborator.
Benchmarking and Results
Benchmarking Methodology
Evaluation Metrics:
Agent performance was measured using accuracy, token consumption, duration, and error rate, all collected automatically with LangSmith, which logs inputs, outputs, intermediate steps, tokens, and execution time for reproducibility and debugging.
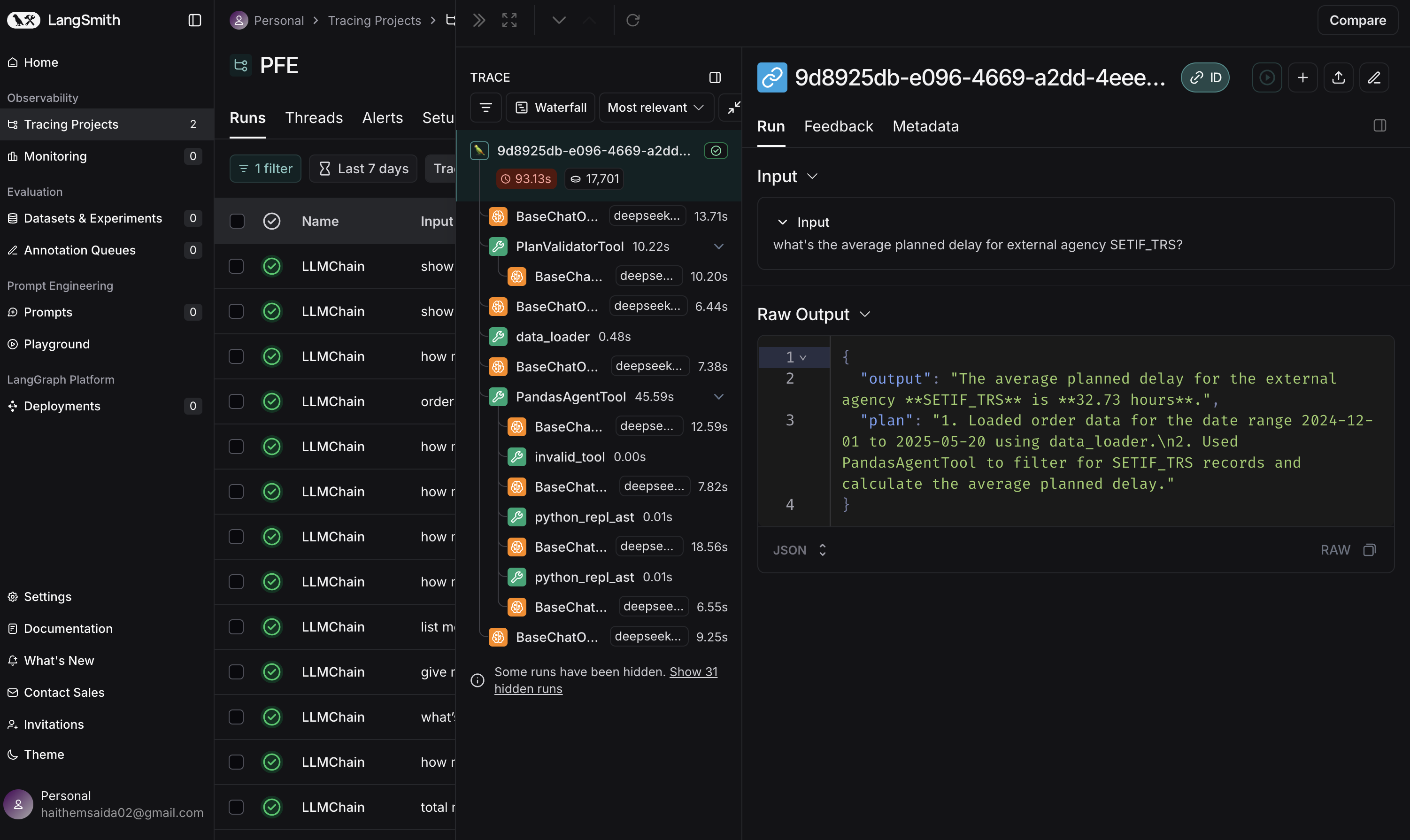 Figure 6: LangSmith Metrics Collection
Figure 6: LangSmith Metrics CollectionHybrid Evaluation Framework:
We used a two-step evaluation for natural language responses:
- SBERT semantic similarity: Quickly compares generated and reference answers (θ = 0.8).
- LLM-as-a-Judge: Handles low-confidence cases, assessing accuracy, completeness, relevance, clarity, and terminology.
This hybrid approach ensures efficient yet context-aware evaluation, capturing nuances that simple similarity metrics might miss.
 Figure 7: Hybrid Evaluation Pipeline
Figure 7: Hybrid Evaluation PipelineBenchmark Dataset and Testing: We manually curated a dataset of 100 natural language queries (87 ordinary queries on inventory, orders, suppliers, and KPIs, plus 13 out-of-scope queries to test robustness). Each query included ground-truth pandas code and human-readable answers for evaluation.
Testing was executed locally on a MacBook Air M1 using Python 3.13.2 and the Ollama framework (Nous Hermes 2 - Mistral 7B - DPO), with LangSmith logging all metrics. The evaluation applied the two-step hybrid approach to compute accuracy, duration, and token usage.
Benchmarking Results and Analysis
Model Selection Rationale: The initial evaluation used DeepSeek V3, chosen for its strong reasoning capabilities, cost-performance balance, and API accessibility.
Results Overview:
| Metric | Result |
|---|---|
| Accuracy | 83% overall (81.61% ordinary, 92.31% OOS) |
| Avg. Token Consumption | 18,667.24 tokens/query |
| Avg. Duration | 80 seconds/query |
| Error Rate | 0% (0/100 queries) |
The agent demonstrated robust performance, handling ordinary and out-of-scope queries reliably, with no critical failures.
Qualitative Observations:
- Strong performance on tabular summarization, ratio computation, and filtering tasks.
- Minor hallucinations occurred for ambiguous queries.
- OOS queries produced polite speculative answers, reflecting reasoning in the absence of explicit refusal training.
What's Next:
While the system performs well, there's room to grow. The 100-query test set is a solid start but doesn't cover every supply chain scenario. Future improvements include expanding the dataset, testing different LLMs to find the best fit for each agent, and fine-tuning the evaluation process as the agents evolve.
Conclusion
SmartSCM Assistant demonstrates the power of multi-agent systems in making data analysis accessible to non-technical users. By combining LangChain's agent framework with specialized tools and careful architecture design, it's possible to create intelligent systems that bridge the gap between natural language and complex data operations.
Acknowledgments
This project wouldn't have been possible without the support and guidance of several key people:
- Benafia Mohamed – My teammate who collaborated with me throughout this project.
- Kherbachi Hamid – My professor who provided valuable academic guidance.
- Anis Idir – My supervisor whose expertise and mentorship were invaluable.
Project Link: GitHub Repository
Full Report: Detailed PDF Documentation