Layout-Aware Multimodal RAG for Complex Document Understanding
A structure-aware RAG pipeline combining layout detection, OCR, and vision-language models to enable question answering over complex technical documents.
Table of Contents
- Introduction
- The Problem
- The Approach
- System Architecture
- Layout Detection
- Document Structure Reconstruction
- Figure Understanding
- Structure-Aware Chunking
- Observability
- Conclusion
- GitHub Repository
Introduction
Technical documents such as industrial reports or scientific papers contain rich information, but in highly complex formats: multi-column layouts, figures, tables, captions, and hierarchical sections.
Traditional RAG pipelines applied to PDFs rely on naive parsing strategies that ignore document structure, leading to poor retrieval quality and unreliable answers.
In this work, we present a layout-aware multimodal RAG system that reconstructs the document structure before performing retrieval and generation.
The Problem
Standard PDF-based RAG systems suffer from several limitations:
- loss of document structure (sections, hierarchy)
- unreliable text extraction
- inability to leverage figures and diagrams
- naive chunking strategies that break context
- weak grounding of generated answers
These issues are critical when dealing with complex technical documents.
The Approach
To address these limitations, the system combines multiple components:
- layout detection
- OCR-based text extraction
- vision-language understanding of figures
- document structure reconstruction
- structure-aware chunking
- vector search
- LLM-based answer generation
The system ensures that all responses are:
strictly grounded in the document content
System Architecture
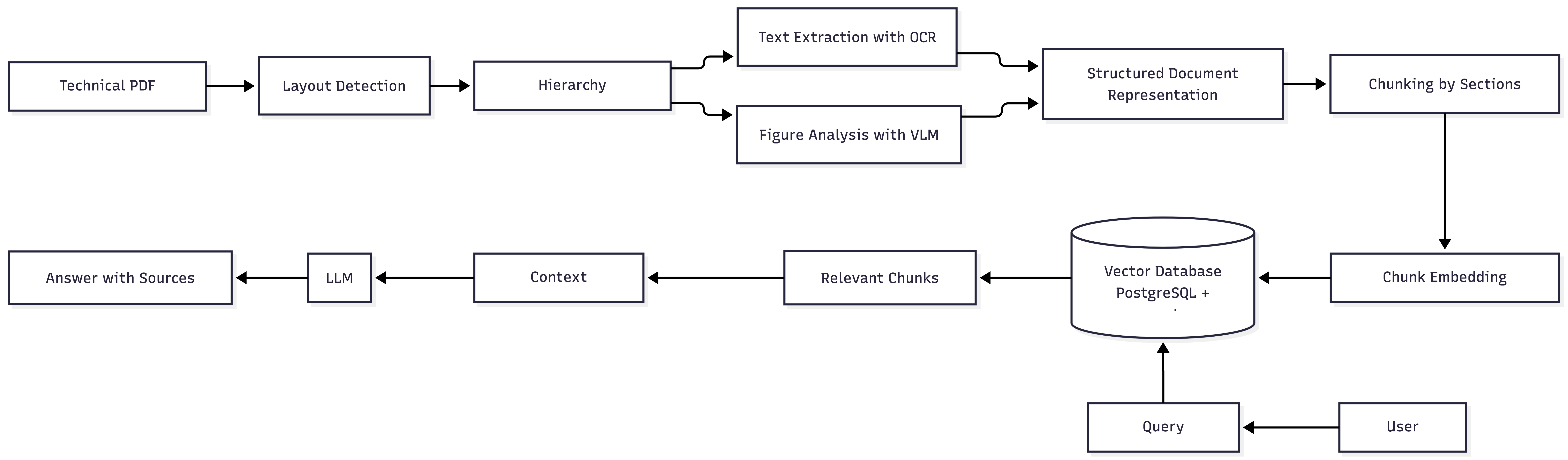
The pipeline follows a multi-stage process:
Document → Layout → OCR → Structure → Chunking → Embedding → Retrieval → LLM
Each stage enriches the document representation.
Layout Detection
A key component is document layout analysis.
The system uses DocLayout-YOLO to detect:
- titles
- paragraphs
- figures
- captions
- tables
Each detected element is associated with:
- a bounding box
- a page number
- a semantic label
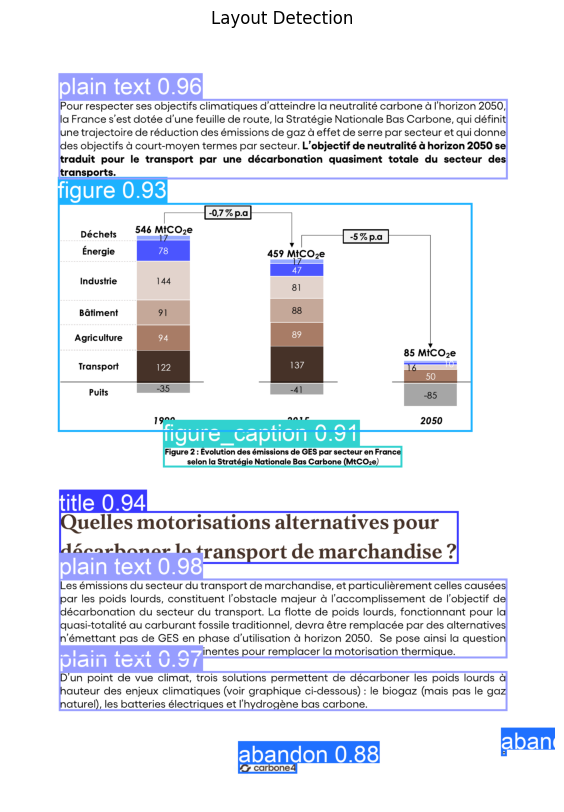
This preserves spatial relationships, which are essential for understanding document structure.
Document Structure Reconstruction
After layout detection, the system reconstructs the logical hierarchy:
Chapter
├── Section
│ ├── Subsection
│ │ ├── Paragraphs
│ │ ├── Figures
│ │ └── Tables
The process includes:
- detecting chapter pages using heuristics
- identifying section titles
- ordering elements based on spatial position
- associating content with its corresponding section
Each element is enriched with metadata:
- chapter
- chapter index
- section title
- page number
- bounding box
This produces a structured document representation.
Figure Understanding
Technical documents often contain critical information in figures and diagrams.
To capture this, the system integrates a Vision-Language Model (VLM):
- Detect figures during layout analysis
- Crop images using bounding boxes
- Generate textual descriptions
These descriptions are then:
- integrated into the document content
- indexed alongside text
This enables multimodal reasoning over the document.
Structure-Aware Chunking
Instead of naive fixed-size chunking, the system uses structure-aware chunking.
Principles:
- group content by section
- keep figures aligned with text
- preserve semantic coherence
A 200-character overlap is added to maintain context continuity.
This significantly improves retrieval quality.
Observability
The system collects key metrics:
- query latency
- token usage
- generation time
- retrieved chunks
These metrics allow:
- analysis of retrieval behavior
- evaluation of generation quality
- identification of failure cases
This makes the pipeline suitable for RAG experimentation and optimization.
Conclusion
This system goes beyond standard RAG pipelines by integrating:
- computer vision
- document understanding
- multimodal AI
It provides a strong foundation for:
- document assistants
- technical report analysis
- industrial Document AI systems
Ultimately, it enables building systems capable of understanding both the structure and content of complex documents.
GitHub Repository
You can explore the full implementation here